大数据常用组件总结
作者:佚名 来源:辰乐游戏 时间:2020-04-30 00:00:00
大数据常用组件总结
Hadoop生态圈各常用组件介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的特点。
Hadoop的核心是YARN,HDFS和MapReduce。Hdfs是分布式文件存储系统,用于存储海量数据;MapReduce是并行处理框架,实现任务分解和调度。Hadoop可以用来搭建大型数据仓库,对海量数据进行存储、分析、处理和统计等业务,功能十分强大。
Hadoop具有成熟的生态系统,包括众多的开源工具,从下图可以大致看出Hadoop生态圈的庞大。

图1 hadoop生态圈
下面对其中常用的组件进行介绍。
一、 HDFS
Hdfs是hadoop的核心组件,hdfs上的文件被分成块进行存储,默认块的大小是64M,块是文件存储处理的逻辑单元。
HDFS是Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,管理数据块映射,处理客户端的读写请求,配置副本策略,管理HDFS的名称空间;
SecondaryNameNode:是NameNode的冷备份,分担NameNode的工作量,合并fsimage和fsedits然后再发给NameNode,定期同步元数据映像文件和修改日志,当NameNode发生故障时,备份转正。
DataNode:是Slave节点,负责存储client发来的数据块block,执行数据块的读写操作,定期向NameNode发送心跳信息。
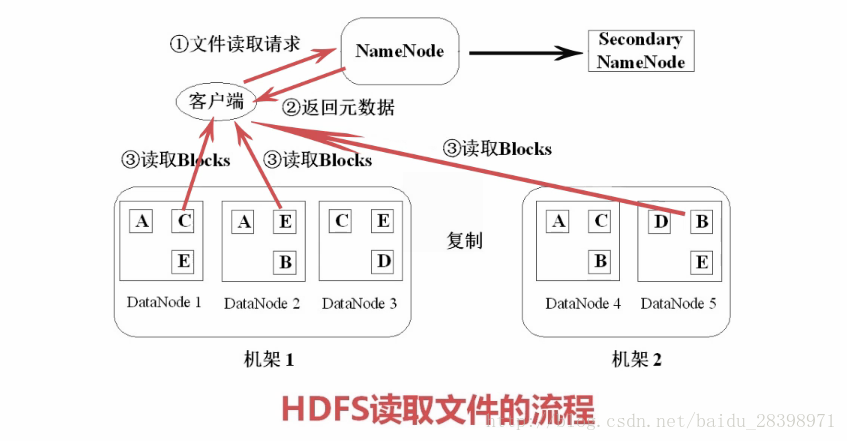
图2 hdfs 读文件流程
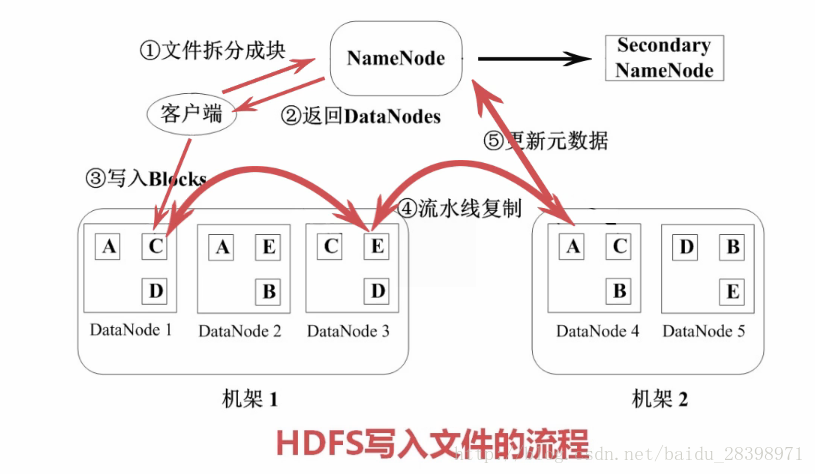
图3 hdfs写文件流程
Hdfs的特点:
1. 数据冗余,硬件容错,每个数据块有三个备份;
2. 流式的数据访问,数据写入不易修改;
3. 适合存储大文件,小文件会增加NameNode的压力。
Hdfs的适用性与局限性;
1. 适合数据批量读写,吞吐量高;
2. 不适合做交互式应用,低延迟很难满足;
3. 适合一次写入多次读取,顺序读写;
4. 不支持多用户并发写相同文件。
二、 MapReduce
MapReduce的工作原理用一句话概括就是,分而治之,然后归约,即将一个大任务分解为多个小任务(map),并行执行后,合并结果(reduce)。
整个MapReduce的过程大致分为Map-->Shuffle(排序)-->Combine(组合)-->Reduce。
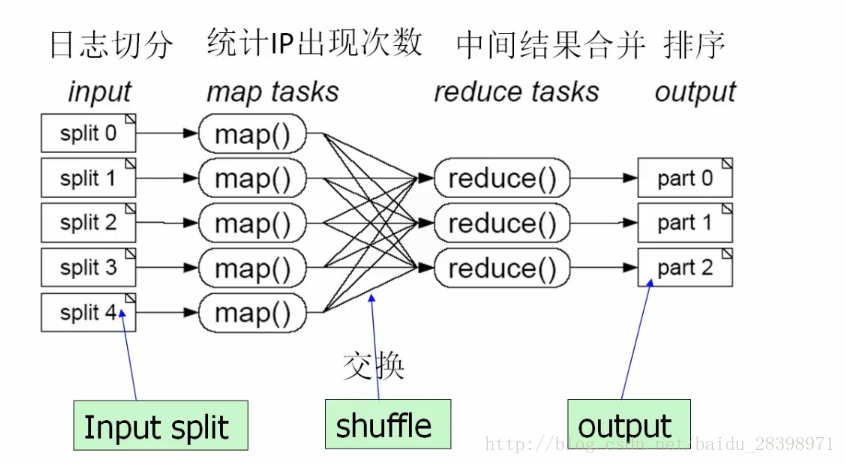
图4 MapReduce工作过程
1.将文件拆分成splits(片),并将每个split按行分割形成<key,value>对。这一步由MapReduce框架自动完成,其中偏移量即key值;
2.将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对;
3.得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行Shuffle(排序),并执行Combine过程,将key值相同得value值累加,得到Mapper的最终输出结果;
4.Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对。
三、 YARN
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
1.ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
(1)调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(ResourceContainer,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
(2) 应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
2. ApplicationMaster(AM)
用户提交的每个应用程序均包含1个AM,主要功能包括:
1) 与RM调度器协商以获取资源(用Container表示);
2) 将得到的任务进一步分配给内部的任务;
3) 与NM通信以启动/停止任务;
4) 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
3. NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
4. Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
5. YARN工作流程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是启动ApplicationMaster;
第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
如图5所示,YARN的工作流程分为以下几个步骤:
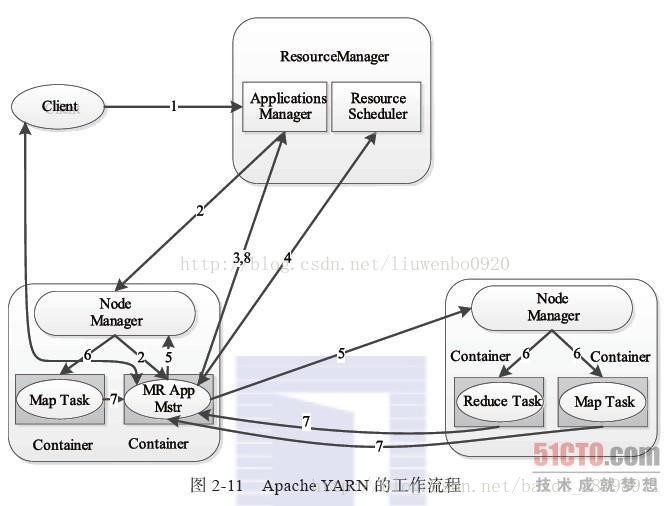
图5 YARN的工作流程
Step1:用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等;
Step2:ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster;
Step3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7;
Step4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源;
Step5:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务;
Step6:NodeManager为任务设置运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
Step7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态;
Step8:应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
四、 Hive
Hive是构建在Hadoop HDFS上的一个数据仓库,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,其本质是将SQL转换为MapReduce程序。
数据仓库是一个面向主题的、集成的、不可更新的、随时间变化的数据集合,它用于支持企业或组织的决策分析处理。
Hive的表其实就是HDFS的目录/文件。
1.Hive的体系结构
Hive默认采用的是Derby数据库进行元数据的存储(metastore),也支持mysql数据库。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性,表的数据所在目录等。
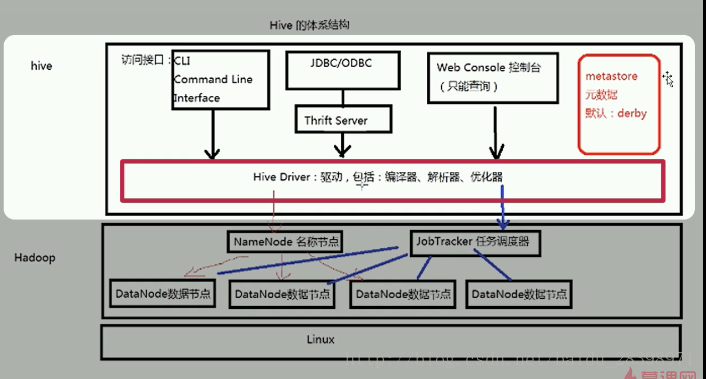
图6 Hive的体系结构
2.HQL的执行过程
解释器、编译器、优化器完成HQL查询语句从词语分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后的MapReduce调用执行。
3.Hive安装的三种模式
1.嵌入模式,数据存储在hive自带的derby数据库,只允许一个连接,多用于本地演示demo;
2.本地模式,一般是mysql,与hive位于同一台服务器,允许多连接,但实际生产环境并不用这种模式;
3.远程模式,mysql安装在远程服务器上,允许多连接,多用于实际生产环境。
4.Hive的数据类型
1)基本数据类型
整型:tinyint/smallint/int/bigint
浮点型:float/double
布尔型:Boolean
字符串:string
2)复杂数据类型
数组类型:Array,有一系列相同数据类型的元素组成
集合类型:Map,包括key->value键值对,可以通过key值访问元素
结构类型:struct,可以包含不同数据类型的元素,可以通过“点语法”的方式获得这些元素
3)时间类型
Date
Timestamp
5.hive与关系型数据库的不同
1) hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
2) hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
3) 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
4) Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
6.Hive的管理
1)命令行方式(CLI方式)
--hive
--hive --service ci
2)web界面方式
端口号:9999
启动方式:hive --service hwi &
通过浏览器访问:http://<IP地址>:9999/hwi/
3)远程服务访问
一个表可以有一个或者多个分区列,Hive将会为分区列上的每个不同的值组合创建单独的数据目录。分区列是虚拟列,要避免分区列名和数据列名相同,可以基于分区列进行查询。
五、 Pig
Pig是yahoo捐献给apache的一个项目,使用SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中。
1.Pig运行模式:
1) 本地模式:Pig运行于本地模式,只涉及单独的一台计算机;本地模式下不支持MapReduce的(线程)并行,因为在当前的hadoop版本中,hadoop的LocalJobRunner 运行器不是一个线程安全的类。
2) MapReduce模式:Pig运行于MapReduce模式,需要能访问一个Hadoop集群,并且需要装上HDFS。
以pig命令方式启动:
(1):pig -x local (local模式)
(2)pig -x mapreduce (集群模式)
以java命令启动模式:
(1),java -cp pig.jar org.opache.pig.Main -xlocal (local模式)
(2),java -cp pig.jar org.opache.pig.Main -xmapreduce (集群模式)
2.Pig调用方式:
1) Grunt shell方式:通过交互的方式,输入命令执行任务;
2) Pig script方式:通过script脚本的方式来运行任务。我们可以把pig的一系列处理,封装成一个pig脚本文件,后缀名以.pig结尾,正如我们把linux命令封装在.sh的脚本里,这样执行起来非常方便,而且容易管理。
3.pig的注释:
(1)多行注释:/*pig脚本语句*/
(2)当行注释:- - pig脚本语句
4.pig语法
在pig中,pig latin是使用pig来处理数据的基本语法,这类似于我们在数据库系统中使用SQL语句一样。
Pig latin语句,通常组织如下:
(一)一个load声明从文件系统上加载数据
使用load操作和(load/store)函数读数据进入Pig(默认的存储模式是PigStorage);
(二)一系列的转化语句去处理数据
使用filter语句来过滤tuple或一行数据(类似于SQL中的where);使用foreach语句来操作列的数据(类似于 select field1,filed 2 ,.... from table里面限制列返回。);使用group语句来分组(类似SQL里面的group by);使用cogroup,inner join,outerjoin来分组或关联两个以上的表关联(与SQL里的join类似);使用union语句来合并两个以上关系的结果数据,使用split语句可以把一个表拆分为多个分散的小表(注意在这里说表,只是为了方便理解,在pig没有表这一个概念).
(三)一个dump语句,来展示结果或者store语句来存储结果,只有Dump和Store语句能产生输出
使用store操作和load/store函数,可以将结果集写入文件系统中,默认的存储格式是PigStorage,在测试阶段,可以使用dump命令,直接将结果显示在我们的屏幕上,方便调试,在一个生产环境中,一般使用store语句,来永久存储结果集。
pig提供了一写操作符,来帮助我们调试我们的结果:
使用dump语句,显示结果在我们的终端屏幕上;
使用describe语句,来显示我们的schema的关系(类似查看表的结构);
使用explain语句,来显示我们的执行逻辑或物理视图,可以帮助我们查看map,reduce的执行计划;
使用illustrate语句,可以一步步的查看我们的语句执行步骤;
此外,pig还定义了一些非常方面的别名集,来快速帮助我们调试脚本:
dump的别名 \d;describe的别名 \de;explain的别名 \e;illustrate的别名 \i;退出\q.
六、 Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper本质上是一个分布式的小文件存储系统。原本是Apache Hadoop的一个组件,现在被拆分为一个Hadoop的独立子项目,在Hbase(Hadoop的另外一个被拆分出来的子项目,用于分布式环境下的超大数据量的DBMS)中也用到了ZooKeeper集群。
Hadoop,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等。
1. 启动ZK服务: sh bin/zkServer.sh start
2. 查看ZK服务状态: sh bin/zkServer.sh status
3. 停止ZK服务: sh bin/zkServer.sh stop
4. 重启ZK服务: sh bin/zkServer.sh restart
七、 Hbase
1.HBase简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
在hadoop 的各层系统中,HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持;Hadoop MapReduce为HBase提供了高性能的计算能力;Zookeeper为HBase提供了稳定服务和failover机制(failover 又称故障切换,指系统中其中一项设备或服务失效而无法运作时,另一项设备或服务即可自动接手原失效系统所执行的工作);Pig和Hive为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单; Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
Row Key: 行键,Table的主键,Table中的记录按照Row Key排序;
Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number;
Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Hbase shell 常用命令
名称
命令表达式
创建表
create '表名称', '列名称1','列名称2','列名称N'
添加记录
put '表名称', '行名称', '列名称:', '值'
查看记录
get '表名称', '行名称'
查看表中的记录总数
count '表名称'
删除记录
delete '表名' ,'行名称' , '列名称'
删除一张表
先要屏蔽该表,才能对该表进行删除,第一步 disable '表名称' 第二步 drop '表名称'
查看所有记录
scan "表名称"
查看某个表某个列中所有数据
scan "表名称" , ['列名称:']
更新记录
就是重写一遍进行覆盖
相关阅读
更多资讯






大家都喜欢
-
 庆余年手游,庆余年官网盛大下载
庆余年手游,庆余年官网盛大下载 -
 阴阳师体验服_阴阳师体验服积分版_阴阳师体验服中文版下载
阴阳师体验服_阴阳师体验服积分版_阴阳师体验服中文版下载 -
 LOL手游体验服下载_LOL手游体验服下载最新官方版 V1.0.8.2下载 _LOL手游体验服下载中文版下载
LOL手游体验服下载_LOL手游体验服下载最新官方版 V1.0.8.2下载 _LOL手游体验服下载中文版下载 -
 王者荣耀 体验服app_王者荣耀 体验服appapp下载_王者荣耀 体验服appios版
王者荣耀 体验服app_王者荣耀 体验服appapp下载_王者荣耀 体验服appios版 -
 绝地求生全军出击体验服iphone版_绝地求生全军出击体验服iphone版手机版安卓
绝地求生全军出击体验服iphone版_绝地求生全军出击体验服iphone版手机版安卓 -
 Google Play 商店,Google Play 商店下载,谷歌商店官方下载
Google Play 商店,Google Play 商店下载,谷歌商店官方下载 -
 龙与勇士手游下载
龙与勇士手游下载 -
 地下城与勇士 Mapp_地下城与勇士 M安卓版app_地下城与勇士 M 手机版免费app
地下城与勇士 Mapp_地下城与勇士 M安卓版app_地下城与勇士 M 手机版免费app -
 红月传奇手游下载
红月传奇手游下载 -
 咪噜游戏_手游公益服_bt手游_变态版手游_手游盒子
咪噜游戏_手游公益服_bt手游_变态版手游_手游盒子 -
 星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载
星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载 -
 猎国下载app下载_猎国下载ios版
猎国下载app下载_猎国下载ios版 -
 战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏
战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏 -
 修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载
修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载 -
 我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载
我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载 -
 部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载
部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载
热门文章





- 精品游戏
- 最热榜单







- 星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载 2.0
- 猎国下载app下载_猎国下载ios版 2.0
- 战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏 2.0
- 修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载 2.0
- 我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载 2.0
- 部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载 2.0
 趣键盘极速版下载_趣键盘极速版下载app下载_趣键盘极速版下载下载 2.0
趣键盘极速版下载_趣键盘极速版下载app下载_趣键盘极速版下载下载 2.0 幻世轩辕手游下载_幻世轩辕手游下载小游戏_幻世轩辕手游下载中文版下载 2.0
幻世轩辕手游下载_幻世轩辕手游下载小游戏_幻世轩辕手游下载中文版下载 2.0 九州缥缈录手游下载官网下载手机版_九州缥缈录手游下载官网下载手机版 2.0
九州缥缈录手游下载官网下载手机版_九州缥缈录手游下载官网下载手机版 2.0 G位app下载_G位app下载电脑版下载_G位app下载安卓版下载 2.0
G位app下载_G位app下载电脑版下载_G位app下载安卓版下载 2.0
 龙脉OL手游下载_龙脉OL手游下载下载_龙脉OL手游下载ios版下载 2.0
龙脉OL手游下载_龙脉OL手游下载下载_龙脉OL手游下载ios版下载 2.0 问道小米版手游下载_问道小米版手游下载下载_问道小米版手游下载ios版下载 2.0
问道小米版手游下载_问道小米版手游下载下载_问道小米版手游下载ios版下载 2.0 释放情绪下载_释放情绪下载电脑版下载_释放情绪下载app下载 2.0
释放情绪下载_释放情绪下载电脑版下载_释放情绪下载app下载 2.0 蜀山战神手游下载_蜀山战神手游下载手机游戏下载_蜀山战神手游下载官方正版 2.0
蜀山战神手游下载_蜀山战神手游下载手机游戏下载_蜀山战神手游下载官方正版 2.0 扬琴调音器软件下载_扬琴调音器软件下载中文版_扬琴调音器软件下载中文版 2.0
扬琴调音器软件下载_扬琴调音器软件下载中文版_扬琴调音器软件下载中文版 2.0 他圈app下载_他圈app下载中文版_他圈app下载最新版下载 2.0
他圈app下载_他圈app下载中文版_他圈app下载最新版下载 2.0 古琴调音器app免费下载_古琴调音器app免费下载攻略_古琴调音器app免费下载app下载 2.0
古琴调音器app免费下载_古琴调音器app免费下载攻略_古琴调音器app免费下载app下载 2.0 猫咪冲锋队下载_猫咪冲锋队下载下载_猫咪冲锋队下载ios版下载 2.0
猫咪冲锋队下载_猫咪冲锋队下载下载_猫咪冲锋队下载ios版下载 2.0 人人漫画家app下载_人人漫画家app下载中文版_人人漫画家app下载攻略 2.0
人人漫画家app下载_人人漫画家app下载中文版_人人漫画家app下载攻略 2.0 印象app下载_印象app下载积分版_印象app下载最新版下载 2.0
印象app下载_印象app下载积分版_印象app下载最新版下载 2.0