阿里RocketMQ消息队列原理&最佳实践
作者:佚名 来源:辰乐游戏 时间:2020-06-15 00:00:00
阿里RocketMQ消息队列原理&最佳实践
前言:
晓杰最近在面试JAVA,这个是面试官问到的问题!希望大家也学习下!共同进步!
一、 MQ背景&选型
消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性。主要具有以下优势:
- 削峰填谷(主要解决瞬时写压力大于应用服务能力导致消息丢失、系统奔溃等问题)
- 系统解耦(解决不同重要程度、不同能力级别系统之间依赖导致一死全死)
- 提升性能(当存在一对多调用时,可以发一条消息给消息系统,让消息系统通知相关系统)
- 蓄流压测(线上有些链路不好压测,可以通过堆积一定量消息再放开来压测)
目前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相比于Rabbitmq、kafka具有主要优势特性有:
• 支持事务型消息(消息发送和DB操作保持两方的最终一致性,rabbitmq和kafka不支持)
• 支持结合rocketmq的多个系统之间数据最终一致性(多方事务,二方事务是前提)
• 支持18个级别的延迟消息(rabbitmq和kafka不支持)
• 支持指定次数和时间间隔的失败消息重发(kafka不支持,rabbitmq需要手动确认)
• 支持consumer端tag过滤,减少不必要的网络传输(rabbitmq和kafka不支持)
• 支持重复消费(rabbitmq不支持,kafka支持)
Rocketmq、kafka、Rabbitmq的详细对比,请参照下表格:

二、RocketMQ集群概述
1. RocketMQ集群部署结构
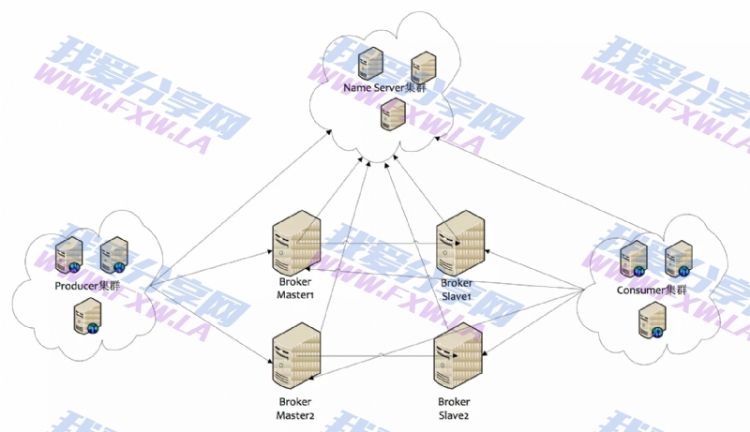
1) Name Server
Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
2) Broker
Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的Broker Name,不同的Broker Id来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。
每个Broker与Name Server集群中的所有节点建立长连接,定时(每隔30s)注册Topic信息到所有Name Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收到心跳,则Name Server断开与Broker的连接。
3) Producer
Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
Producer每隔30s(由ClientConfig的pollNameServerInterval)从Name server获取所有topic队列的最新情况,这意味着如果Broker不可用,Producer最多30s能够感知,在此期间内发往Broker的所有消息都会失败。
Producer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到心跳数据,则关闭与Producer的连接。
4) Consumer
Consumer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可用时,Consumer最多最需要30s才能感知。
Consumer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送心跳数据,则关闭连接;并向该Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。
当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来了,因此会有少量的消息丢失。但是一旦master恢复,未同步过去的消息会被最终消费掉。
消费者对列是消费者连接之后(或者之前有连接过)才创建的。我们将原生的消费者标识由 {IP}@{消费者group}扩展为 {IP}@{消费者group}{topic}{tag},(例如xxx.xxx.xxx.xxx@mqtest_producer-group_2m2sTest_tag-zyk)。任何一个元素不同,都认为是不同的消费端,每个消费端会拥有一份自己消费对列(默认是broker对列数量*broker数量)。新挂载的消费者对列中拥有commitlog中的所有数据。
如果有需要,可以查看Rocketmq更多源码解析
三、 Rocketmq如何支持分布式事务消息
场景
A(存在DB操作)、B(存在DB操作)两方需要保证分布式事务一致性,通过引入中间层MQ,A和MQ保持事务一致性(异常情况下通过MQ反查A接口实现check),B和MQ保证事务一致(通过重试),从而达到最终事务一致性。
原理:大事务 = 小事务 + 异步
1. MQ与DB一致性原理(两方事务)
流程图
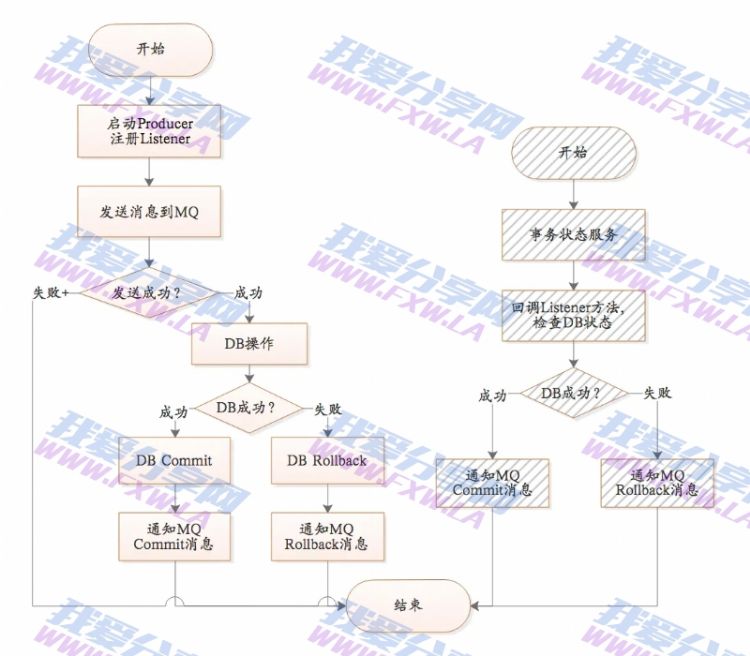
上图是RocketMQ提供的保证MQ消息、DB事务一致性的方案。
MQ消息、DB操作一致性方案:
1)发送消息到MQ服务器,此时消息状态为SEND_OK。此消息为consumer不可见。
2)执行DB操作;DB执行成功Commit DB操作,DB执行失败Rollback DB操作。
3)如果DB执行成功,回复MQ服务器,将状态为COMMIT_MESSAGE;如果DB执行失败,回复MQ服务器,将状态改为ROLLBACK_MESSAGE。注意此过程有可能失败。
4)MQ内部提供一个名为“事务状态服务”的服务,此服务会检查事务消息的状态,如果发现消息未COMMIT,则通过Producer启动时注册的TransactionCheckListener来回调业务系统,业务系统在checkLocalTransactionState方法中检查DB事务状态,如果成功,则回复COMMIT_MESSAGE,否则回复ROLLBACK_MESSAGE。
说明:
上面以DB为例,其实此处可以是任何业务或者数据源。
以上SEND_OK、COMMIT_MESSAGE、ROLLBACK_MESSAGE均是client jar提供的状态,在MQ服务器内部是一个数字。
TransactionCheckListener 是在消息的commit或者rollback消息丢失的情况下才会回调(上图中灰色部分)。这种消息丢失只存在于断网或者rocketmq集群挂了的情况下。当rocketmq集群挂了,如果采用异步刷盘,存在1s内数据丢失风险,异步刷盘场景下保障事务没有意义。所以如果要核心业务用Rocketmq解决分布式事务问题,建议选择同步刷盘模式。
2. 多系统之间数据一致性(多方事务)
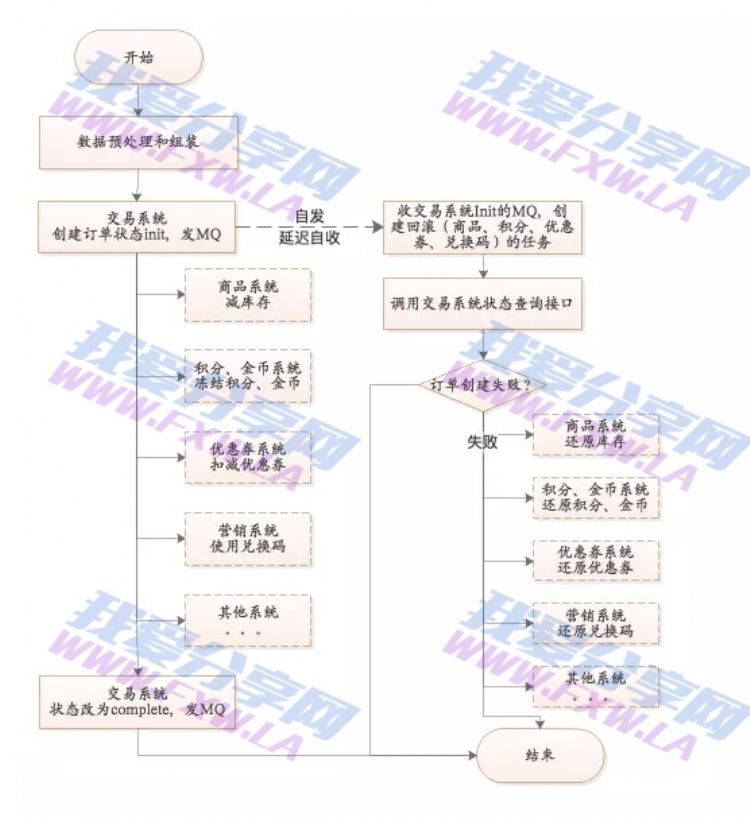
当需要保证多方(超过2方)的分布式一致性,上面的两方事务一致性(通过Rocketmq的事务性消息解决)已经无法支持。这个时候需要引入TCC模式思想(Try-Confirm-Cancel,不清楚的自行百度)。
以上图交易系统为例:
1)交易系统创建订单(往DB插入一条记录),同时发送订单创建消息。通过RocketMq事务性消息保证一致性
2)接着执行完成订单所需的同步核心RPC服务(非核心的系统通过监听MQ消息自行处理,处理结果不会影响交易状态)。执行成功更改订单状态,同时发送MQ消息。
3)交易系统接受自己发送的订单创建消息,通过定时调度系统创建延时回滚任务(或者使用RocketMq的重试功能,设置第二次发送时间为定时任务的延迟创建时间。在非消息堵塞的情况下,消息第一次到达延迟为1ms左右,这时可能RPC还未执行完,订单状态还未设置为完成,第二次消费时间可以指定)。延迟任务先通过查询订单状态判断订单是否完成,完成则不创建回滚任务,否则创建。 PS:多个RPC可以创建一个回滚任务,通过一个消费组接受一次消息就可以;也可以通过创建多个消费组,一个消息消费多次,每次消费创建一个RPC的回滚任务。 回滚任务失败,通过MQ的重发来重试。
以上是交易系统和其他系统之间保持最终一致性的解决方案。
3.案例分析
1) 单机环境下的事务示意图
如下为A给B转账的例子。
- 上一篇:WPS Office Pro 永久激活码
- 下一篇:Firefox在线查密码数据泄露
相关阅读
更多资讯





大家都喜欢
-
 庆余年手游,庆余年官网盛大下载
庆余年手游,庆余年官网盛大下载 -
 阴阳师体验服_阴阳师体验服积分版_阴阳师体验服中文版下载
阴阳师体验服_阴阳师体验服积分版_阴阳师体验服中文版下载 -
 LOL手游体验服下载_LOL手游体验服下载最新官方版 V1.0.8.2下载 _LOL手游体验服下载中文版下载
LOL手游体验服下载_LOL手游体验服下载最新官方版 V1.0.8.2下载 _LOL手游体验服下载中文版下载 -
 王者荣耀 体验服app_王者荣耀 体验服appapp下载_王者荣耀 体验服appios版
王者荣耀 体验服app_王者荣耀 体验服appapp下载_王者荣耀 体验服appios版 -
 绝地求生全军出击体验服iphone版_绝地求生全军出击体验服iphone版手机版安卓
绝地求生全军出击体验服iphone版_绝地求生全军出击体验服iphone版手机版安卓 -
 Google Play 商店,Google Play 商店下载,谷歌商店官方下载
Google Play 商店,Google Play 商店下载,谷歌商店官方下载 -
 龙与勇士手游下载
龙与勇士手游下载 -
 地下城与勇士 Mapp_地下城与勇士 M安卓版app_地下城与勇士 M 手机版免费app
地下城与勇士 Mapp_地下城与勇士 M安卓版app_地下城与勇士 M 手机版免费app -
 红月传奇手游下载
红月传奇手游下载 -
 咪噜游戏_手游公益服_bt手游_变态版手游_手游盒子
咪噜游戏_手游公益服_bt手游_变态版手游_手游盒子 -
 星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载
星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载 -
 猎国下载app下载_猎国下载ios版
猎国下载app下载_猎国下载ios版 -
 战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏
战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏 -
 修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载
修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载 -
 我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载
我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载 -
 部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载
部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载
热门文章





- 精品游戏
- 最热榜单







- 星云纪手游下载_星云纪手游下载ios版下载_星云纪手游下载app下载 2.0
- 猎国下载app下载_猎国下载ios版 2.0
- 战火纷争手游下载_战火纷争手游下载破解版下载_战火纷争手游下载小游戏 2.0
- 修真情缘变态版下载_修真情缘变态版下载安卓手机版免费下载_修真情缘变态版下载app下载 2.0
- 我的世界手机版下载免费_我的世界手机版下载免费安卓版下载_我的世界手机版下载免费ios版下载 2.0
- 部族之光手游下载iOS游戏下载_部族之光手游下载中文版下载 2.0
 趣键盘极速版下载_趣键盘极速版下载app下载_趣键盘极速版下载下载 2.0
趣键盘极速版下载_趣键盘极速版下载app下载_趣键盘极速版下载下载 2.0 幻世轩辕手游下载_幻世轩辕手游下载小游戏_幻世轩辕手游下载中文版下载 2.0
幻世轩辕手游下载_幻世轩辕手游下载小游戏_幻世轩辕手游下载中文版下载 2.0 九州缥缈录手游下载官网下载手机版_九州缥缈录手游下载官网下载手机版 2.0
九州缥缈录手游下载官网下载手机版_九州缥缈录手游下载官网下载手机版 2.0 G位app下载_G位app下载电脑版下载_G位app下载安卓版下载 2.0
G位app下载_G位app下载电脑版下载_G位app下载安卓版下载 2.0
 龙脉OL手游下载_龙脉OL手游下载下载_龙脉OL手游下载ios版下载 2.0
龙脉OL手游下载_龙脉OL手游下载下载_龙脉OL手游下载ios版下载 2.0 问道小米版手游下载_问道小米版手游下载下载_问道小米版手游下载ios版下载 2.0
问道小米版手游下载_问道小米版手游下载下载_问道小米版手游下载ios版下载 2.0 释放情绪下载_释放情绪下载电脑版下载_释放情绪下载app下载 2.0
释放情绪下载_释放情绪下载电脑版下载_释放情绪下载app下载 2.0 蜀山战神手游下载_蜀山战神手游下载手机游戏下载_蜀山战神手游下载官方正版 2.0
蜀山战神手游下载_蜀山战神手游下载手机游戏下载_蜀山战神手游下载官方正版 2.0 扬琴调音器软件下载_扬琴调音器软件下载中文版_扬琴调音器软件下载中文版 2.0
扬琴调音器软件下载_扬琴调音器软件下载中文版_扬琴调音器软件下载中文版 2.0 他圈app下载_他圈app下载中文版_他圈app下载最新版下载 2.0
他圈app下载_他圈app下载中文版_他圈app下载最新版下载 2.0 古琴调音器app免费下载_古琴调音器app免费下载攻略_古琴调音器app免费下载app下载 2.0
古琴调音器app免费下载_古琴调音器app免费下载攻略_古琴调音器app免费下载app下载 2.0 猫咪冲锋队下载_猫咪冲锋队下载下载_猫咪冲锋队下载ios版下载 2.0
猫咪冲锋队下载_猫咪冲锋队下载下载_猫咪冲锋队下载ios版下载 2.0 人人漫画家app下载_人人漫画家app下载中文版_人人漫画家app下载攻略 2.0
人人漫画家app下载_人人漫画家app下载中文版_人人漫画家app下载攻略 2.0 印象app下载_印象app下载积分版_印象app下载最新版下载 2.0
印象app下载_印象app下载积分版_印象app下载最新版下载 2.0